-
基于不同监督强度分类的语义分割综述:A Breif Survey on Semantic Segmentation with Deep Learning

引言:语义分割是计算机视觉中一项具有挑战性的任务。近年来,深度学习技术的应用大大提高了语义分割的性能。人们提出了大量的新方法。本文旨在对基于深度学习的语义分割方法的研究进展进行简要综述。全文将该领域的研究按其监督程度进行了分类,即完全监督方法、弱监督方法和半监督方法。文章还讨论了当前研究的共同挑战,并提出了该领域的几个有价值的发展研究点。本综述旨在让读者了解深度学习时代语义分割研究的进展和面临的挑战。
论文链接:https://www.sciencedirect.com/science/article/pii/S0925231220305476
基于不同监督强度分类的语义分割综述:A Breif Survey on Semantic Segmentation with Deep Learning
如何读论文?
第一步,看标题+摘要+结论+图表(了解论文在干什么)
第二步,从头到尾读到最后(了解论文的各个部分)
第三步,精读,理解创新点、思路、动机
语义分割介绍

图(a)是原始输入图像
语义分割-图(b):通过给定一张图片,语义分割能给每一个像素分配相应的标签/类别
图片分类-图©: 图片分类能告诉我们,什么物体存在于这张图片中
目标检测-图(d): 不仅仅需要知道图片中需要存在什么物体,还应该知道他们的坐标
实例分割-图(e): 与语义分割相似,区别是检测每一个物体作为一个独立的类别,相同的类别有不同的车,例如图片中的车,不同的车有着不同的颜色
全景分割-图(f): 类似于语义分割+实例分割的结合体,不仅要识别出每一个物体,也需要识别出背景
常见的主干网络
网络 提出时间 贡献 AlexNet 2012 引发了深度学习的浪潮,首次将模型训练应用于GPU中 VGG 2014 大量使用3x3或5x5的卷积核构建更深层的网络 ResNet 2016 解决了梯度消失和梯度爆炸等问题,使得构建深层网络成为可能 MobileNetV3 2019 使用dw卷积,倒残差结构,加入自注意力机制,在精度损失较小的情况下,使模型更轻量化 ViT 2020 首次将自然语言处理的方法应用到视觉任务中来,取得了较大的精度提升 🚀从不同监督强度介绍分割方法
全监督
1.基于语义的方法
context:翻译为上下文,我所理解的上下文,就是图像中的每一个像素点不可能是孤立的,一个像素一定和周围像素是有一定的关系的,大量像素的互相联系才产生了图像中的各种物体,所以上下文特征就指像素以及周边像素的某种联系。

在图像需要全局信息的问题中,都能很好的应用膨胀卷积,膨胀卷积保持参数个数不变的情况下增大了卷积核的感受野,让每个卷积输出都包含较大范围的信息
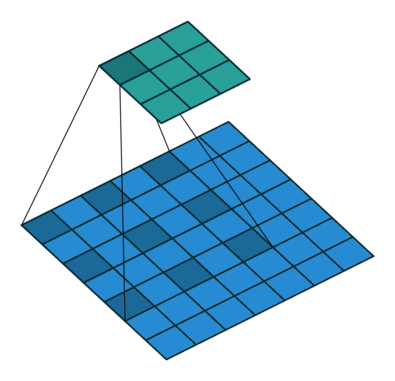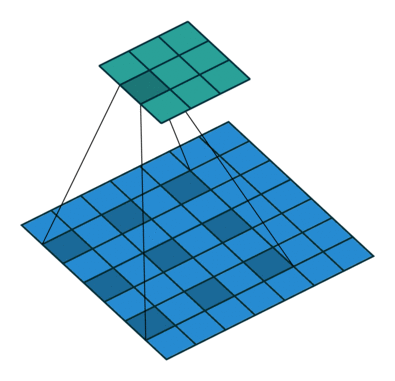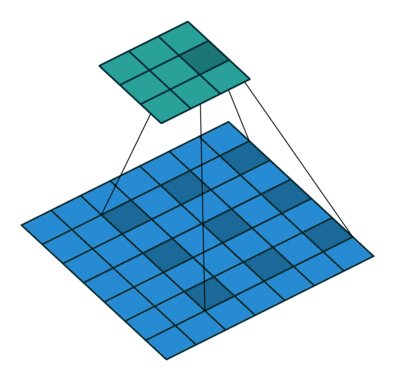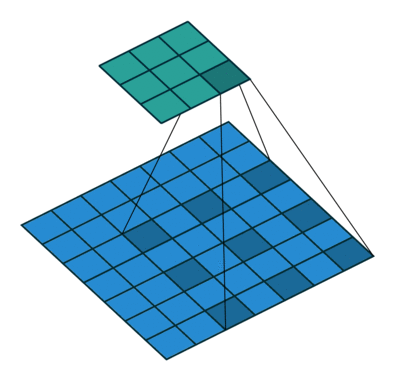
使用膨胀卷积前后,分割效果对比:

2.特征增强法
-
在深层提取的特征具有更强的语义感知能力,但由于池化和步幅卷积,失去了空间细节。
-
来自浅层的特征更注重细节,如强边缘。在这种情况下,这两种类型的特征的适当合作有可能提高语义分割的性能。
利用语义感知能力+空间细节能力提高性能

3.反卷积法

下图展示了转置卷积中不同s和p的情况
s=1, p=0, k=3 s=2, p=0, k=3 s=2, p=1, k=3 
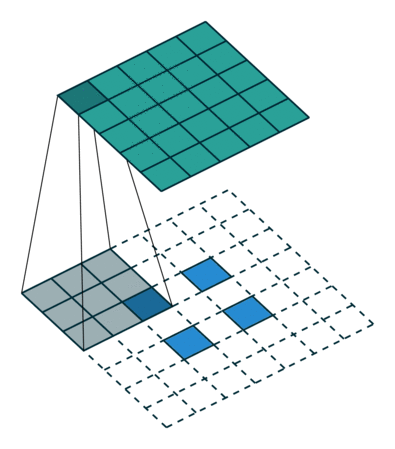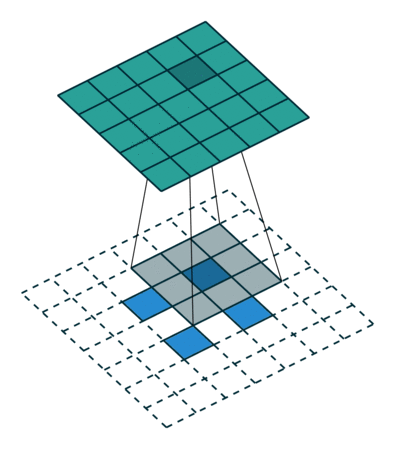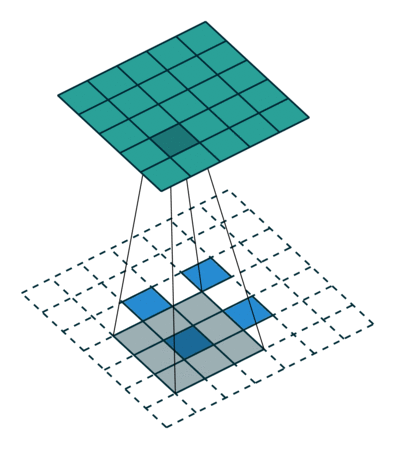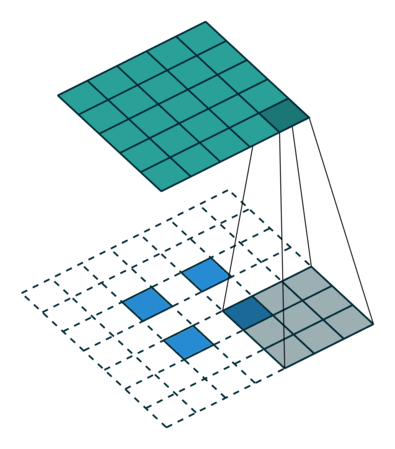

下列是一些基于反卷积的分割方法:

4.RNN法
利用局部或者全局的上下文依赖关系,使用RNN去检索上下文信息,以此作为分割的一部分依据

5.对抗生成网络(Gan)法
图形分割过程中,运用判别器对分割对象的局部属性、全局结构特点进行深入学习,以此获取不同像素间的有效空间关系,GAN用于扩展训练数据,提升训练效果。
- 首先对对抗网络进行预训练,
- 然后使用对抗性损失来微调分割网络,如下图所示。左边的分割网络将 RGB 图像作为输入,并产生每个像素的类别预测。
- 右边的对抗网络将标签图作为输入并生成类标签(1代表真实标注,0代表合成标签)


6.RGBD法
利用激光雷达、双目相机等工具,生成深度图象,用于辅助语义分割
引入深度信息后,其提供的额外结构信息能够有效辅助复杂和困难场景下的分割。比如,与室外场景相比,由于语义类别繁杂、遮挡严重、目标外观差异较大等原因,室内场景的分割任务要更难实现。此时,在结合深度信息的情况下,能够有效降低分割的难度。

7.实时法

- 限制输入尺寸
- 修改膨胀率
- 🔥修改卷积方式

弱监督
根据弱监督信号的形式,常见的弱监督语义分割可分为以下四类:
- 图像级标注:仅标注图像中相关物体所属的类别,是最简单的标注;
- 物体点标注:标注各个物体上某一点,以及相应类别;
- 物体框标注:标注各个物体所在的矩形框,以及相应类别;
- 物体划线标注:在各个物体上划一条线,以及相应类别

1.只提供分类标签
监督信息:这是一张包含xxx的图片?
优点:标注过程相对简单,不需要使用像素标注,样本获取相对容易,整体工作量相对较小
缺点:图像级标注的方法显得有些简单粗陋,很难取得良好的、符合预期的分割效果
标注结果如下:

基于图像级标注的弱监督语义分割大多采用多模块串联的形式进行

- 首先,利用图像级标注的图像类别标签,通过单标签或多标签分类的方式,训练出一个分类模型
- 然后,该分类模型通过计算图像中相应类别的类别特征响应图CAM来当作分割伪标签的种子区域
- 接着,使用优化算法(如 CRF、AffinityNet等)优化和扩张种子区域,获得最终的像素级的分割伪标签
- 最后,使用图像数据集和分割伪标签训练传统的分割算法(如 Deeplab 系列)
2.粗糙涂鸦分割标注
监督信息:包含涂鸦线条和涂鸦点的图像
基本原理:首先基于涂鸦点和涂鸦线条对图像进行标注处理,然后基于标注处理后的图片进行训练
标注结果如下:

半监督
1.域自适应法
目的:域适应的问题背景是两个同类的数据集,由于光照、角度等不同,存在域差异(分布不同),来自不同域的图片可能在外观上有很大的不同,但是他们的分割输出是结构化的,共享很多的相似性,比如空间布局和局部上下文。
增强模型的迁移能力!

2.小样本学习
可以理解为需要模型具有很强的迁移能力,只需要少量的样本就可以完成新类别的识别
目前在基于小样本学习的语义分割领域中,最广泛采用的技术路线图是构建新颖的结构,以巧妙地利用尽可能多的额外有用信息。
当下的挑战、未来的方向
挑战
- 精确度和速度的平衡
- 依赖高质量的训练数据
- 不同数据中模型难以迁移
未来方向
- 实时的语义分割
- 无监督分割
- 有遮挡物体的分割
- 实例/全景分割
完成新类别的识别
-
-
相关阅读:
数论-整除分块
Android 12.0 自定义仿小米全面屏手势导航左右手势滑动返回UI效果
flume+es+kibana日志系统
精确杂草控制植物检测模型的改进推广
c++四种强制类型转换
JS中字符串一些常用的方法
particles.js粒子特效(常用登录页背景)
[ 漏洞复现篇 ] Apache Shiro 身份认证绕过漏洞 (CVE-2022-32532)
【Python】对中文排序
关于git flow的一点思考
- 原文地址:https://blog.csdn.net/henghuizan2771/article/details/127432485