-
【Pandas总结】第四节 Pandas 缺失值处理(通过实例进行演示)
核心知识点
一、检测空值:
isnull()notnull()df.isnull()与df.notnull():用于检测dataframe 或者 series
二、删除空值:
dropna()格式:
df.dropna(DataFrame, axis='',how='', inplace='')参数 说明 DataFrame 待处理的df axis 删除行还是删除列,传入 0或者’index’ 代表行,传入1或者’columns’ 代表列how ‘any’ 表示任何值为空都删除,‘all’ 表示所有值为空才删除 inplace True表示修改当前df;false表示返回修改后的df, 默认为false举例可以参考下面的实例;
三、填充空值:
fillna()格式:
df.fillna(value='', method='', axis='',inplace='')参数 说明 value 用于填充的值,可以是单个值或者字典(key是列名,value是用于填充的值) method ‘ffill’:即forword fill ,使用前一个不为空的值进行填充
‘bfill’:即backfill, 使用后一个不为空的值进行填充axis 删除行还是删除列,传入 0或者’index’ 代表行,传入1或者’columns’ 代表列inplace True表示修改当前df;false表示返回修改后的df, 默认为false举例可以参考下面的实例;
实例
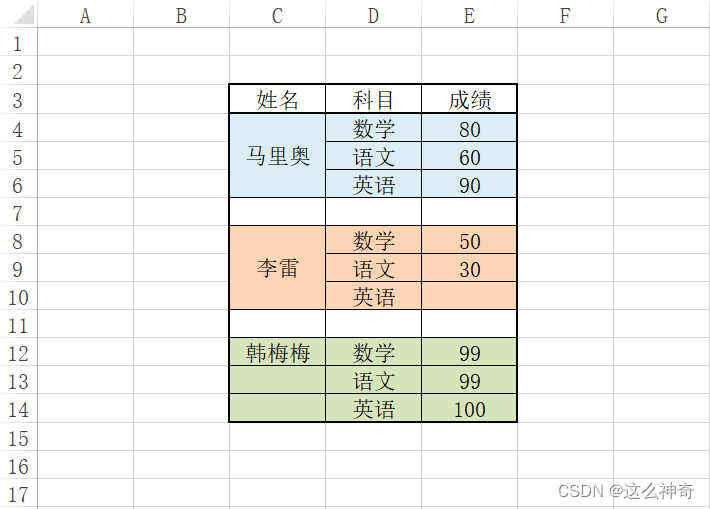
现实中,经常有一些非常漂亮的Excel, 例如下面的例子中的Excel。 这种Excel虽然好看,但是却不满足数据处理的要求,数据处理时,需要的是一个标准的表格,不包含合并单元格等这些格式; 这就需要我们对数据进行处理,这里举一个例子,供大家参考:
结果对比
处理前: 好看但不好用!
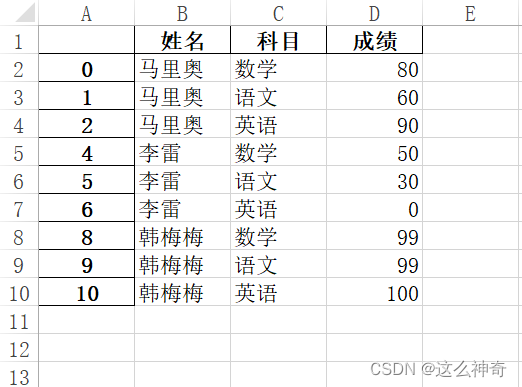
处理后:不好看,但好用!
一、读入数据
data_path=r"E:\VSCODE\2_numpy_pandas\pandas\data.xlsx" df=pd.read_excel(data_path) print(df)- 1
- 2
- 3

二、去掉无用的行
可以看到,读出的数据并非是我们想要的,我们需要的数据只有蓝色区域内,这时我们需要对读入的数据进行处理;首先我们需要把无用的行去掉,这里可以使用
pd.read_excel函数中的参数来修改,详细的内容可以参考:【Pandas总结】第二节 Pandas 的数据读取_pd.read_csv()的使用详解 , 将代码修改为:df=pd.read_excel(data_path,skiprows=2)- 1
这样处理后,打印的结果为:

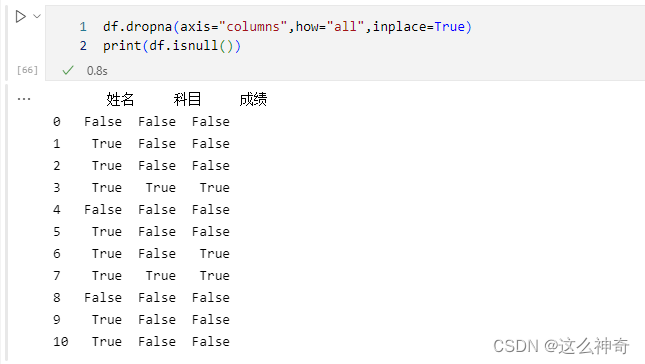
三、 去掉全部为空值的列
使用
drop.na来处理全部为空值的列;df.dropna(axis="columns",how="all",inplace=True) print(df)- 1
- 2
可以看到,全部为空值的列没有了;

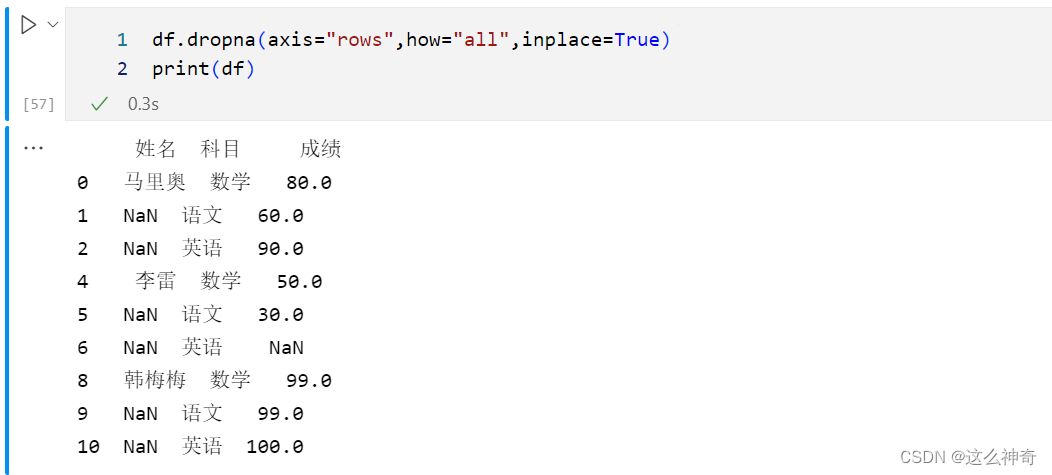
四、 去掉全部为空值的行
与去除列的方式一样,只要将
axis的参数改为rows, 即可删除全部为空值的列;代码如下:df.dropna(axis="rows",how="all",inplace=True) print(df)- 1
- 2
五、将成绩为NaN的单元格,填充为0
使用
fillna()来处理全部为空值的列;df = df.fillna({"成绩":0}) print(df)- 1
- 2

六、将缺失的姓名填充
df = df.fillna(method='ffill') print(df)- 1
- 2

七、保存到excel中
data_path_new = r"E:\VSCODE\2_numpy_pandas\pandas\data_new.xlsx" df.to_excel(data_path_new)- 1
- 2
-
相关阅读:
第二十三章《斗地主游戏》第2节:系统功能实现
从零开始的PICO教程(4)--- UI界面绘制与响应事件
深度强化学习中深度Q网络(Q-Learning+CNN)的讲解以及在Atari游戏中的实战(超详细 附源码)
卡尔曼家族从零解剖-(07) 高斯分布积分为1,高斯分布线性变换依旧为高斯分布,两高斯函数乘积仍为高斯。
AVL平衡树的插入
Linux安装frp并实现内网穿透
使用scp把另外一台服务器上的文件夹/文件拷贝到当前服务器
含文档+PPT+源码等]精品基于NET实现的旅游景点推荐系统[包运行成功]计算机毕业设计NET毕业设计项目源码
条例26~30(实现)
2530. 执行 K 次操作后的最大分数
- 原文地址:https://blog.csdn.net/weixin_47139649/article/details/126850209