-
NLP标注工具Brat的简单使用
目录
写在前面
今天跟大家分享的是 NLP标注工具 Brat 的简单使用。
1. 背景
Brat 所支持的标注任务有:实体识别、实体关系、事件抽取等;当然也可适配到 Aspect-Based Sentiment Analysis 即方面级情感分析任务的数据标注,可参考情感分析系列之《利用BRAT进行中文情感分析语料标注》[1];
另外,Brat工具可适配到中文标注场景;需要注意的是其安装环境需要为osx或linux系统或linux虚拟环境。
2. Brat的安装与启动

首先从[Brat rapid annotation tool][2]下载安装包「brat-v1.3_Crunchy_Frog.tar.gz」,进行解压和安装。
需要注意的是:解压时需放入一个不含中文字符的目录,如「dataLabeling」。
-
解压
解压命令:tar -xf brat-v1.3_Crunchy_Frog.tar.gz

-
安装
安装命令:./install.sh -u
安装过程中根据提示输入登录名、密码和邮箱等(主要用于后续在标注网页上登录)。
- -> dataLabeling ./install.sh -u
- please the user name that you want to use when logging into brat
- xxx
- please enter a brat password (this shows on screen)
- xxx
- please enter the administrator contact email
- xxx



安装流程大家可参看Installation - brat rapid annotation tool[3],写得非常清楚。
3. Brat的运行
运行命令:python standalone.py

注意这里 python版本为python2 。
如下图所示,运行成功后点击网址(默认为 http://127.0.0.1:8001),即可进入在线标注页面:

点击ok,然后可以看到Examples 和 tutorials ,这两个是官方给的标注示例。
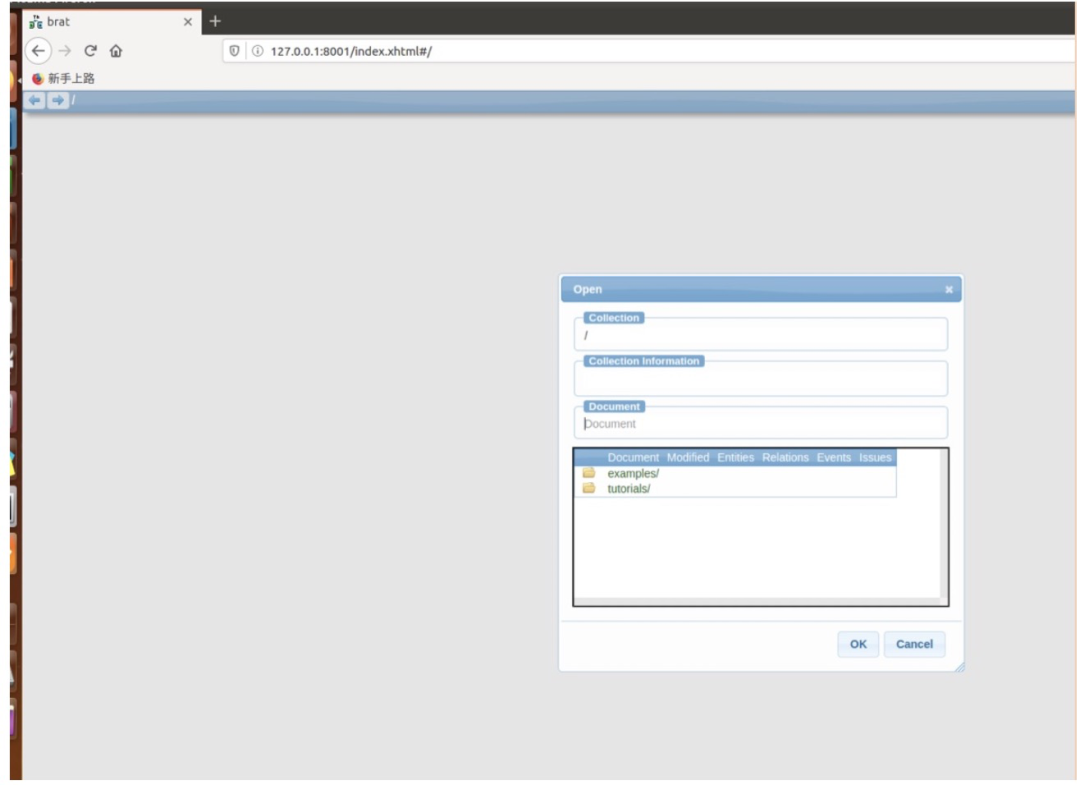

如果要进行标注,需要点击页面右上角brat进行登录,输入刚才安装过程中的用户名和密码:
4. 标注配置与标注
如果要适配到自己的标注任务,需要进行一些配置,具体步骤概括如下:
-
准备原始数据文件
-
准备配置文件 annotation.conf
-
标注界面显示中文标签配置 visual.conf
(1) 原始数据文件准备
根据标注需求,按照句子/段落/篇章整理成文件,每个文件为一个样本,所有样本整合到一个文件夹下,再将该文件夹置于 Brat 安装路径下的 data 目录下。
注意:文本编码格式为utf-8,文件名称为xxx.txt,其中xxx只能为数字或英文。
这里以事件抽取任务标注为例:数据文件统一存放在 Brat 安装路径下的 data目录中的「event_demo」文件夹下;其中,每一个样本文件中包含一个句子。下图展示了名为2.txt的文件中所包含的文本内容:

此外,每个样本文件必须有一个与之对应的空的ann文件,主要用于存放标注后自动生成的标注结果。若没有ann文件,那么当你在页面点击相应文件时是无法打开的。
生成 ann 文件的命令较简单。只需在data目录下,执行命令:
find 目标文件夹名称 -name '*.txt'|sed -e 's|\.txt|.ann|g'|xargs touch(2) 配置文件配置
仍然以事件抽取任务标注为例。首先,我们需要明确:
-
所要标注的事件有哪些,即明确事件类型;
-
每个事件的结构如何,即明确每个事件类型下的事件元素/论元(角色);
-
每个事件元素可以属于哪些实体类型;
-
每个事件元素是必须有,还是可以有可以无,或者有几个。
在以上内容明确以后,再进行配置文件的配置。
这里需要解释一点,就是按照标准事件抽取任务定义来说,事件的元素都是实体,所以我们必须明确每个事件类型下的每一个元素可以属于哪些实体类型。
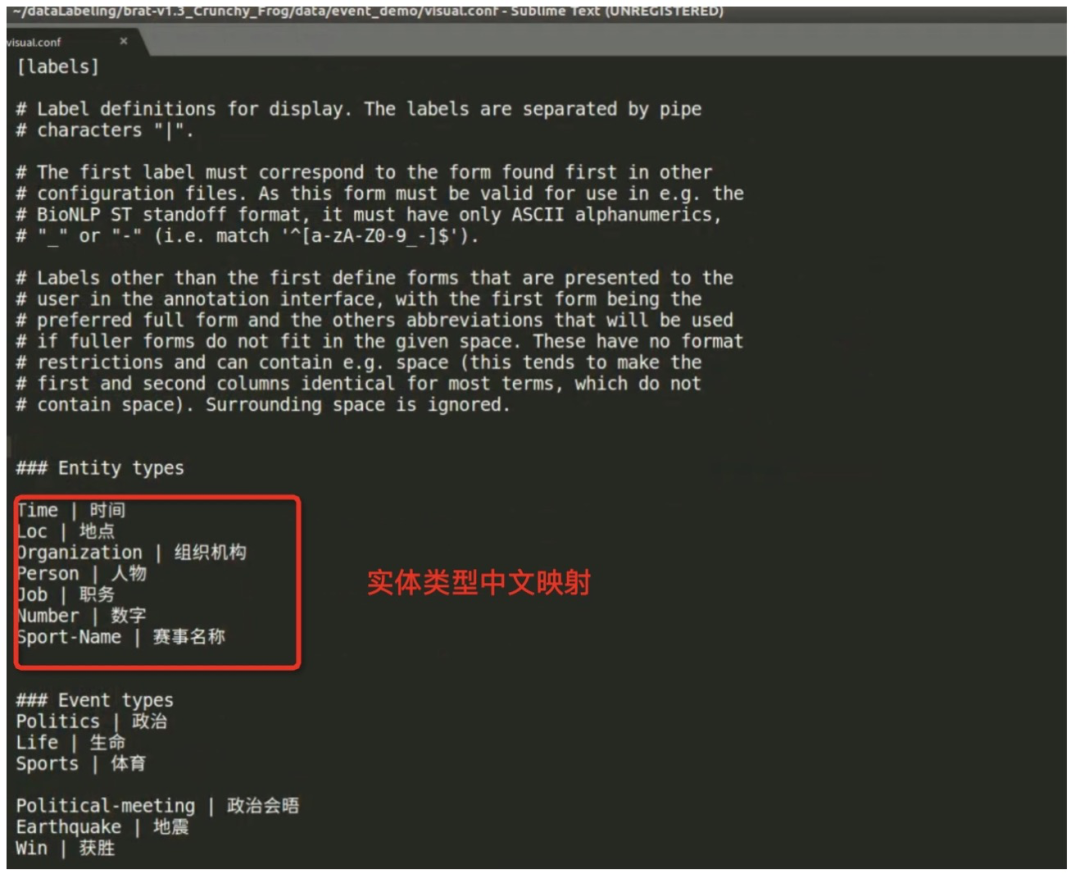
annotation.conf 配置文件放于相应数据文件夹下,比如这里的 event_demo。下图是配置示例,其中共有7类实体,即:时间(Time)、地点(Loc)、组织机构(Organization)、人物(Person)、职务(Job)、数字(Number)、体育赛事活动名称(Sport-Name)。
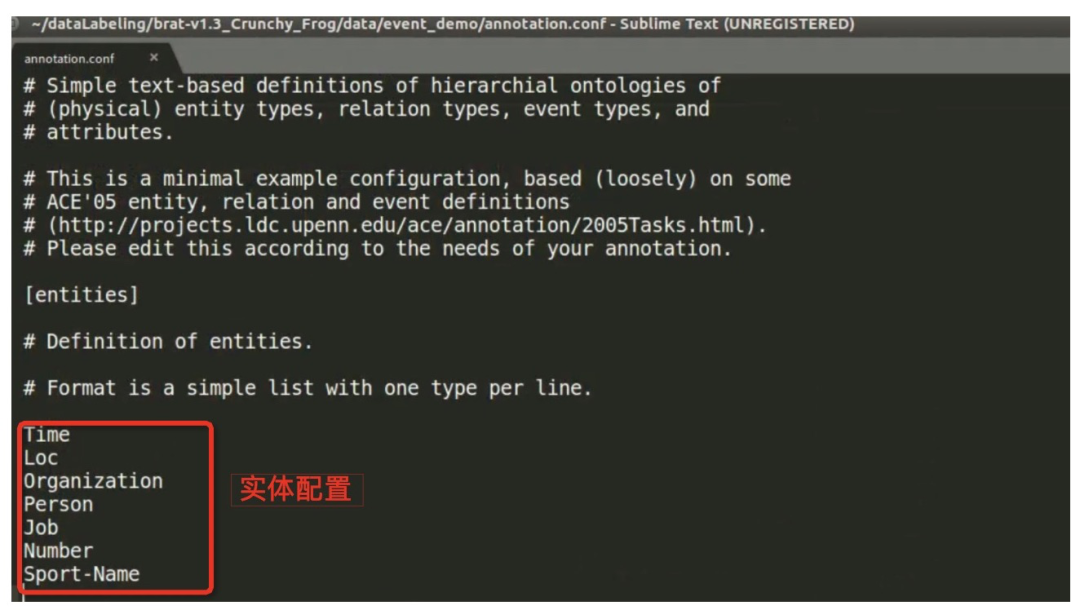
此外,里面共配置了3类事件即政治会晤(Political-meeting)、地震(Earthquake)、获胜(Win)。其中:
-
政治会晤事件中的事件元素有:时间(Time)、地点(Place)、参与者(Participants);
-
地震事件中的事件元素有:时间、地点、震级(Layer)、震源深度(Distance)、死亡人数(Die)、受伤人数(Injure);
-
获胜事件中的事件元素有:时间、胜者(Winner)、败者(Loser)、赛事名称(Name)。

每个类型事件下的每个元素也进行了实体类型约束,比如政治会晤中的参与者元素的实体类型为
,结合实体简称配置,我们可以知道政治会晤中的参与者元素的实体类型为职务、组织机构、人物这三类。其他同理,不再赘述。 另外对于事件元素,?、 *、+则限定了其是否必须,至少有几个,具体可参看实体简称上的解释。
(3) 标注
在标注页面上,选中想要标注的文字,在弹框里勾选其对应的标签即可。
-
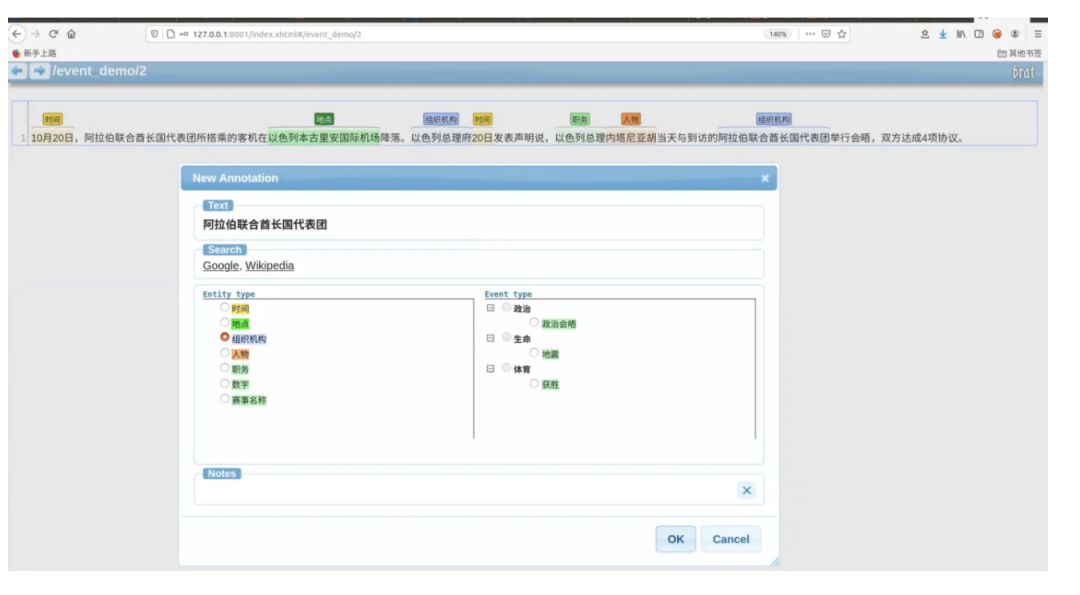
实体标注
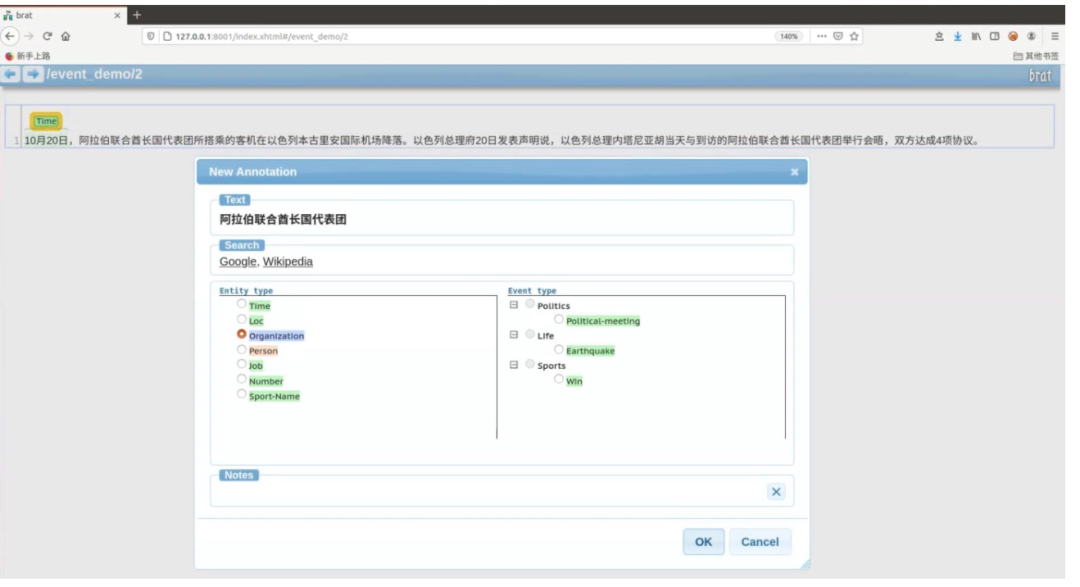
假设选中的文字为实体,那我们就在实体一栏为其选择所属的实体类型,如「10月20日」的实体类型为时间,「阿拉伯联合酋长国代表团」实体类型为组织机构 。

-
触发词与事件类型标注
假设选中的文字为事件的触发词,那么我们就在事件类型一栏为其选择事件类型,如「会晤」一词事件类型为政治会晤。

-
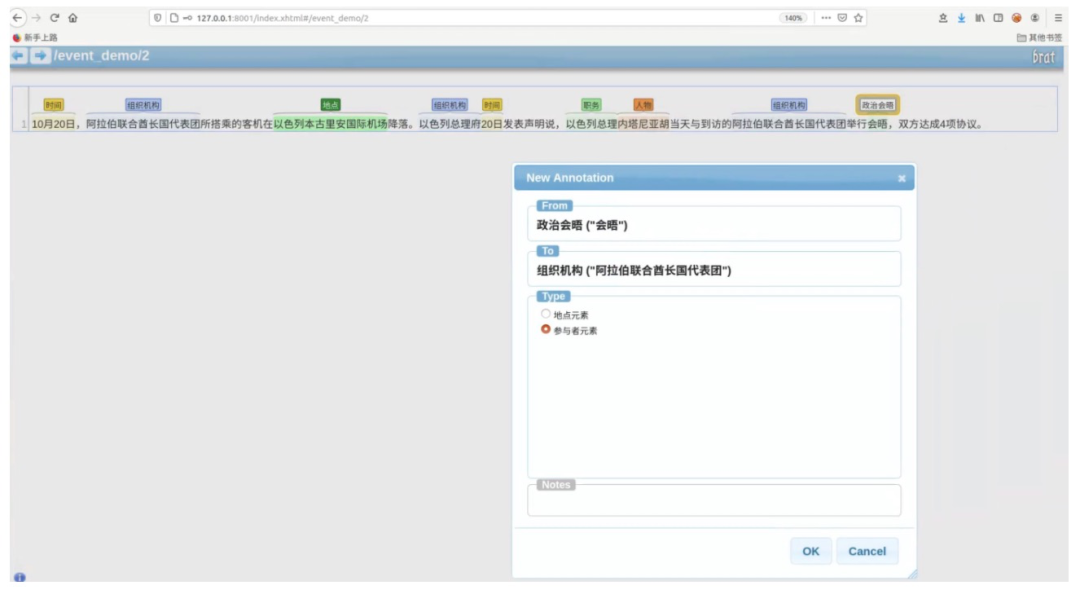
事件元素标注
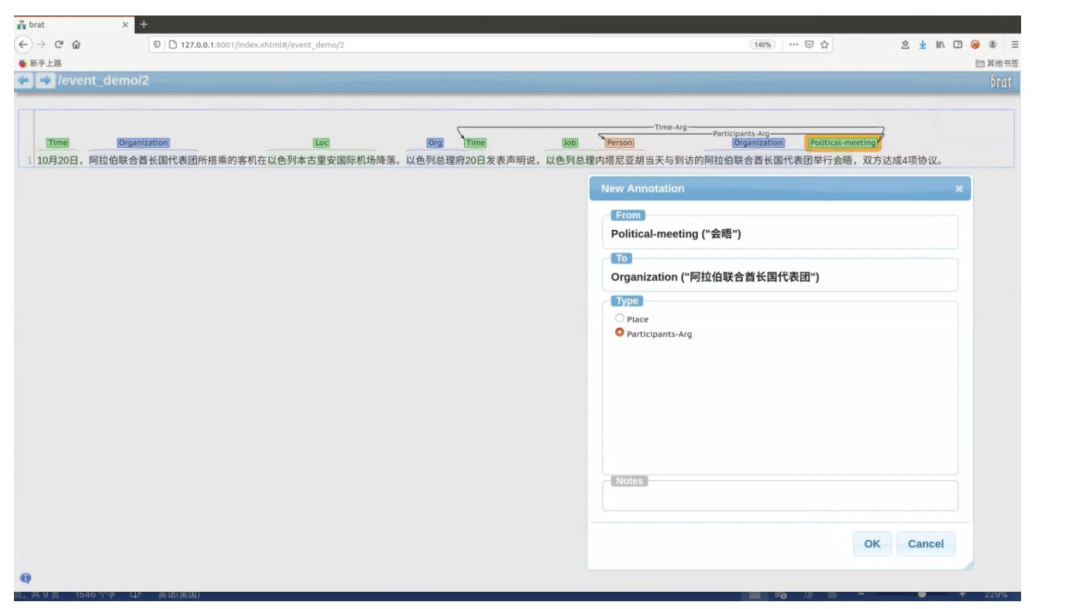
在标完实体与事件触发词后,我们需要做的就是将实体与事件触发词关联起来。操作简单:直接从触发词拉出一条箭头指向相应实体,在弹框里选中该实体在事件中扮演的角色(事件元素)。如「阿拉伯联合酋长代表团」为「会晤」触发的政治会晤事件中的参与者元素。
(4) 中文标签配置
可以看到,在(3)中标注页面显示的都是英文。如果想要对标注人员更友好,最好是在标注页面显示中文。那怎么才能让标注页面显示中文呢?
经过实践,发现想要让标注页面显示中文是不能直接更改配置文件,因为会出各种bug。但是,我们可以配置另外一个文件 visual.conf。
如下图所示,我们只需分别配置 entity types、event types、role types 即可让相关实体类型、事件类型以及论元角色在页面中的标签显示为中文。

需注意的是,Brat本身不支持中文,所以还需要更改server/src/projectconfig.py 文件中第162行代码为:
n = re.sub(u'[^a-zA-Z\u4e00-\u9fa5<>,0-9_-]','_', n)(5) 标注
在配置 visual.conf 文件后,最终,标注页面如下:
-
实体标注
-
触发词与事件类型标注

-
事件元素标注

(6) 标注结果
下面两图分别为地震、获胜事件的标注完成示例图以及对应的 ann 文件中系统根据我们的标注自动生成的标注结果:
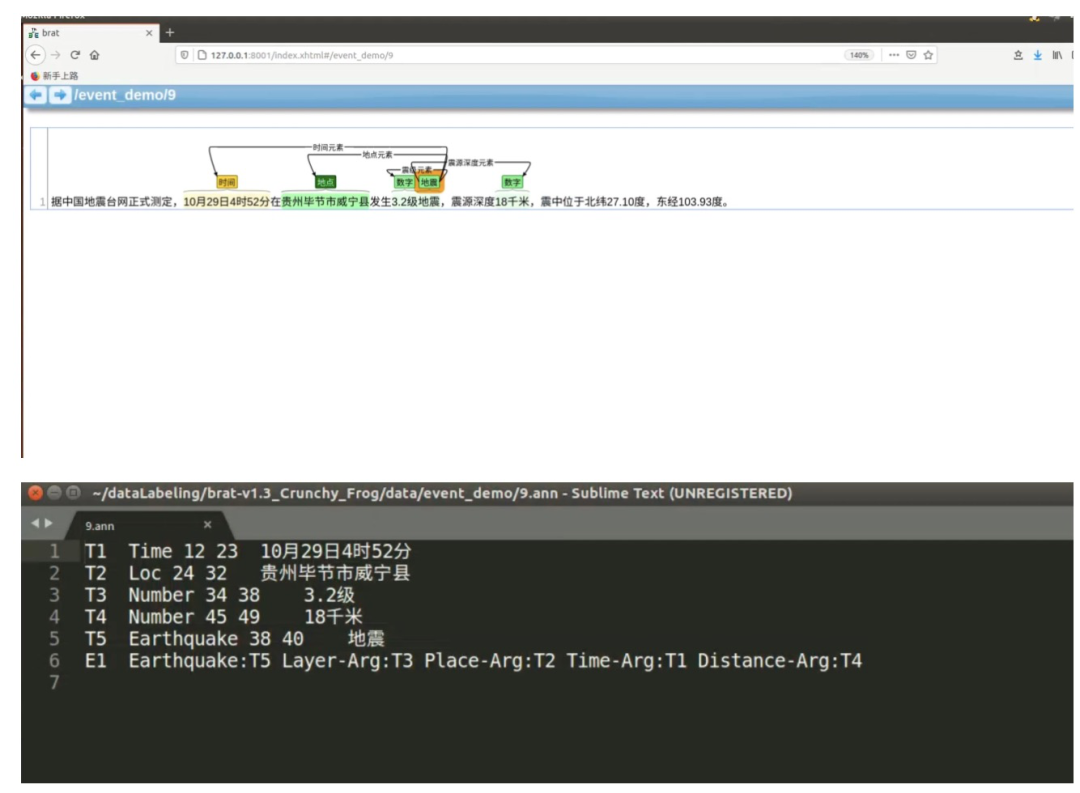
在9.txt文件中,共有4个实体:
-
T1:10月29日4时52分-时间
-
T2:贵州毕节市咸宁县-地点
-
T3:3.2级-数字
-
T4:18千米-数字
共有1个地震事件 E1:
-
事件触发词:地震(T5)
-
事件元素:
-
时间元素:10月29日4时52分
-
地点元素:贵州毕节市咸宁县
-
震级元素:3.2级
-
震源深度元素:18千米
-
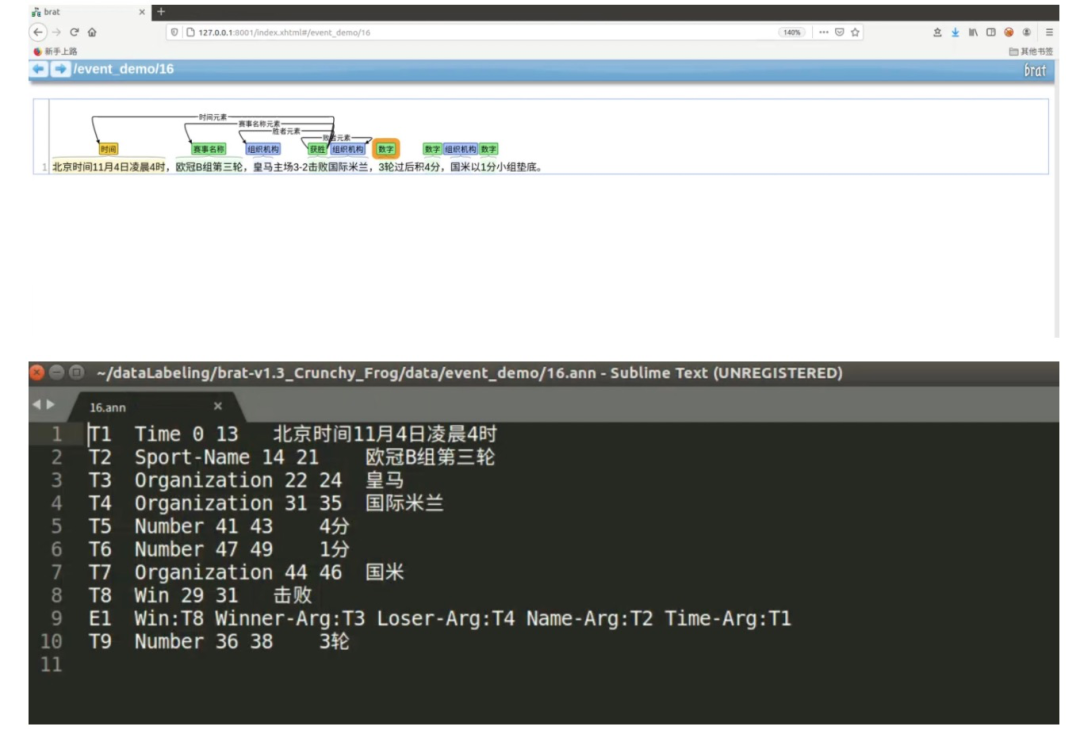
在16.txt文件中,共有7个实体:
-
T1:北京时间11月4日凌晨4点-时间
-
T2:欧冠B组第三轮-赛事名称
-
T3:皇马-组织机构
-
T4:国际米兰-组织机构
-
T5:4分-数字
-
T6:1分-数字
-
T7:国米-组织机构
共有1个获胜事件 E1:
-
事件触发词:击败(T8)
-
事件元素:
-
时间元素:北京时间11月4日凌晨4点-时间
-
赛事名称元素:欧冠B组第三轮-赛事名称
-
胜者元素:皇马
-
败者元素:国际米兰
-
5. 标注与修正示例视频
Brat工具使用总的来说还是蛮简单的,下面的视频展示了一个完整的标注过程:
,时长01:06
当然标错时的修改和删除操作也比较简单,参看下面的视频:
,时长00:33
需要注意的是如果要删除的实体已经关联到了事件,这时需要先去除实体与事件之间的关联即删除相应带事件角色箭头,再删除实体。
总结
最后对 Brat标注工具总结如下:
-
搭建成本低:只需要符合操作系统要求的电脑,即可进行安装和运行;
-
操作简单:成功运行后,明确业务需求/标注需求的人均可进行标注。操作简单,选中相关文本,在弹框中为其选中相应的标签即可;
-
多任务标注:可同时进行实体、实体关系以及事件的标注;
-
标注质量的保证:要保证标注质量,首先需要按照需求进行配置,可以规定每个事件必须要有的元素,以及每个元素有多少,这样可避免一些未标注完全的数据出现;另外标注人员必须对标注任务Schema如事件结构非常了解。
-
多人标注:Brat 也支持多人标注。
-
-
相关阅读:
智能手机收入和出货量双双下滑,造车成本不断增长,小米集团仍面临风险
云原生架构(微服务、容器云、DevOps、不可变基础设施、声明式API、Serverless、Service Mesh)
使用IDEA2022.1创建Maven工程出现卡死问题
225页10万字政务大数据能力平台项目建议书
172版本关闭背钻后自动添加反盘和禁布的功能
LabVIEW高温摩擦磨损测试系统
List的介绍
【正点原子STM32连载】第三十七章 触摸屏实验 摘自【正点原子】MiniPro STM32H750 开发指南_V1.1
Docker跨主机网络通信
直销系统开发是找开发公司还是外包团队?
- 原文地址:https://blog.csdn.net/qq_38735017/article/details/126277949