一、 写在前面
随着深度学习技术的不断发展,模型的训练成本也越来越高。训练一个高效的通用模型,需要大量的训练数据和算力。在很多非大模型相关的常规任务上,往往也需要使用多卡来进行并行训练。在多卡训练中,最为常用的就是分布式数据并行(DistributedDataParallel, DDP)。但是现有的有关DDP的教程和博客比较少,内容也比较分散繁琐。在大多数情况下,我们只需要学会如何使用即可,不需要特别深入地了解原理。为此,写下这个系列博客,简明扼要地介绍一下DDP的使用,抛开繁杂的细节和原理,帮助快速上手使用(All in one blog)。
篇幅较长,分为上下两篇:这篇简要介绍相关背景和理论知识,下篇详细介绍代码框架和搭建流程。
二、什么是分布式并行训练
1. 并行训练
在Pytorch中,有两种并行训练方式:
1)模型并行。模型并行通常是指你的模型非常大,大到一块卡根本放不下,因而需要把模型进行拆分放到不同的卡上。
2)数据并行。数据并行通常用于训练数据非常庞大的时候,比如有几百万张图像用于训练模型。此时,如果只用一张卡来进行训练,那么训练时间就会非常的长。并且由于单卡显存的限制,训练时的batch size不能设置得过大。但是,对于很多模型的性能而言,由于BN层的使用,都会和batch size的大小正相关。此外,很多基于对比学习的训练算法,由于其对负样本的需求,性能也与batch size的大小正相关。因此,我们需要使用多卡训练,不仅可以训练加速,并且可以设置更大的batch size来提升性能。
2. 数据并行
在Pytorch中有两种方式来实现数据并行:
1)数据并行(DataParallel,DP)。DataParallel采用参数服务器架构,其训练过程是单进程的。在训练时,会将一块GPU作为server,其余的GPU作为worker,在每个GPU上都会保留一个模型的副本用于计算。训练时,首先将数据拆分到不同的GPU上,然后在每个worker上分别进行计算,最终将梯度汇总到server上,在server进行模型参数更新,然后将更新后的模型同步到其他GPU上。这种方式有一个很明显的弊端,作为server的GPU其通信开销和计算成本非常大。它需要和其他所有的GPU进行通信,并且梯度汇总、参数更新等步骤都是由它完成,导致效率比较低。并且,随着多卡训练的GPU数量增强,其通信开销也会线性增长。
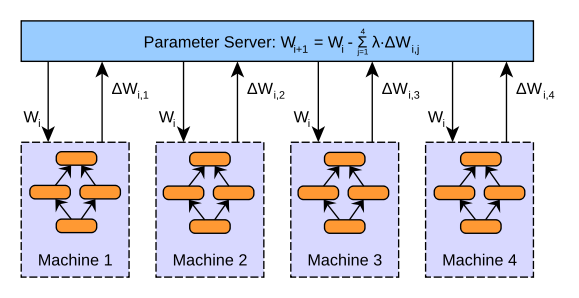
不过DataParallel的代码十分简洁,仅需在原有单卡训练的代码中加上一行即可。
model = nn.DataParallel(model)
如果你的数据集并不大,只有几千的规模,并且你多卡训练时的卡也不多,只有4块左右,那么DataParallel会是一个不错的选择。
关于Parameter Server更详细的原理介绍,可以参考:
一文讀懂「Parameter Server」的分布式機器學習訓練原理
2)分布式数据并行(DistributedDataParallel,DDP)。DDP采用Ring-All-Reduce架构,其训练过程是多进程的。如果要用DDP来进行训练,我们通常需要修改三个地方的代码:数据读取器dataloader,日志输出print,指标评估evaluate。其代码实现略微复杂,不过我们只需要始终牢记一点即可:每一块GPU都对应一个进程,除非我们手动实现相应代码,不然各个进程的数据都是不互通的。Pytorch只为我们实现了同步梯度和参数更新的代码,其余的需要我们自己实现。
三、DDP的基本原理
1. DDP的训练过程
DDP的训练过程可以总结为如下步骤:
1)在训练开始时,整个数据集被均等分配到每个GPU上。每个GPU独立地对其分配到的数据进行前向传播(计算预测输出)和反向传播(计算梯度)。
2)同步各个GPU上的梯度,以确保模型更新的一致性,该过程通过Ring-All-Reduce算法实现。
3)一旦所有的GPU上的梯度都同步完成,每个GPU就会使用这些聚合后的梯度来更新其维护的模型副本的参数。因为每个GPU都使用相同的更新梯度,所以所有的模型副本在任何时间点上都是相同的。
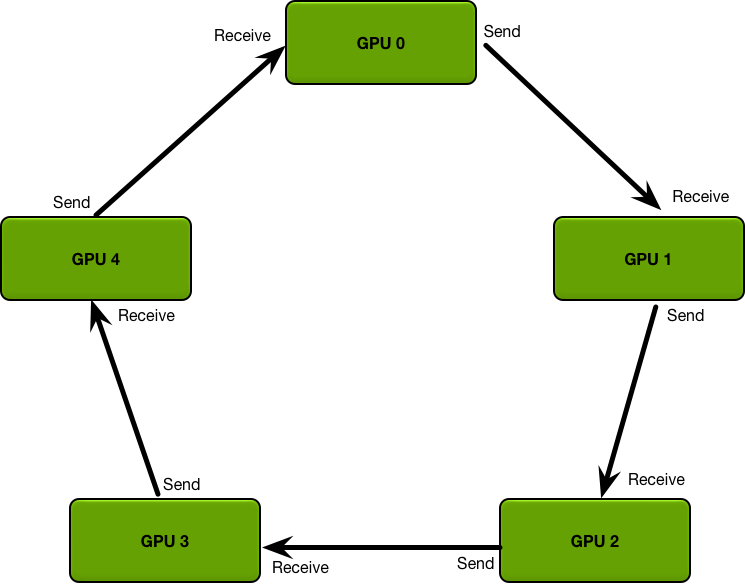
2. Ring-All-Reduce算法
Ring-All-Reduce架构是一个环形架构,所有GPU的位置都是对等的。每个GPU上都会维持一个模型的副本,并且只需要和它相连接的两个GPU通信。
对于第k个GPU而言,只需要接收来自于第k-1个GPU的数据,并将数据汇总后发送给第k+1个GPU。这个过程在环中持续进行,每个GPU轮流接收、聚合并发送梯度。
经过 N 次的迭代循环后(N是GPU的数量),每个GPU将累积得到所有其他GPU的梯度数据的总和。此时,每个GPU上的梯度数据都是完全同步的。
DDP的通信开销与GPU的数量无关,因而比DP更为高效。如果你的训练数据达到了十万这个量级,并且需要使用4卡及以上的设备来进行训练,DDP将会是你的最佳选择。
关于DDP和Ring-All-Reduce算法的更多实现原理和细节,可以参考:
Bringing HPC Techniques to Deep Learning
Pytorch 分散式訓練 DistributedDataParallel — 概念篇
Technologies behind Distributed Deep Learning: AllReduce
四、如何搭建一个Pytorch DDP代码框架
1. 与DDP有关的基本概念
在开始使用DDP之前,我们需要了解一些与DDP相关的概念。
| 参数 | 含义 | 查看方式 |
|---|---|---|
| group | 分布式训练的进程组,每个group可以进行自己的通信和梯度同步 | Group通常在初始化分布式环境时创建,并通过torch.distributed.new_group等API创建自定义groups。 |
| world size | 参与当前分布式训练任务的总进程数。在单机多GPU的情况下,world size通常等于GPU的数量;在多机情况下,它是所有机器上所有GPU的总和。 | torch.distributed.get_world_size() |
| rank | Rank是指在所有参与分布式训练的进程中每个进程的唯一标识符。Rank通常从0开始编号,到world size - 1结束。 | torch.distributed.get_rank() |
| local rank | Local rank是当前进程在其所在节点内的相对编号。例如,在一个有4个GPU的单机中,每个GPU进程的local rank将是0, 1, 2, 3。这个参数常用于确定每个进程应当使用哪个GPU。 | Local rank不由PyTorch的分布式API直接提供,而通常是在启动分布式训练时由用户设定的环境变量,或者通过训练脚本的参数传入。 |
2. 与DDP有关的一些操作
在DDP中,每个进程的数据是互不影响的(除了采用Ring-All-Reduce同步梯度)。如果我们要汇总或者同步不同进程上的数据,就需要用到一些对应的函数。
1)all_reduce
all_reduce操作会在所有进程中聚合每个进程的数据(如张量),并将结果返回给所有进程。聚合可以是求和、取平均、找最大值等。当你需要获得所有进程的梯度总和或平均值时,可以使用all_reduce。这在计算全局平均或总和时非常有用,比如全局平均损失。
一个示例代码如下:
import torch.distributed as dist
tensor_a = torch.tensor([1.0], device=device)
# 所有进程中的tensor_a将会被求和,并且结果会被分配给每个进程中的tensor_a。
dist.all_reduce(tensor_a, op=dist.ReduceOp.SUM)
2)all_gather
all_gather操作用于在每个进程中收集所有进程的数据。它不像all_reduce那样聚合数据,而是将每个进程的数据保留并汇总成一个列表。当每个进程计算出一个局部结果,并且你需要在每个进程中收集所有结果进行分析或进一步处理时,可以使用all_gather。
一个示例代码如下:
import torch
import torch.distributed as dist
# 每个进程有一个tensor_a,其值为当前进程的rank
tensor_a = torch.tensor([rank], device=device) # 假设rank是当前进程的编号
gather_list = [torch.zeros_like(tensor_a) for _ in range(dist.get_world_size())]
# 收集所有进程的tensor_a到每个进程的gather_list
dist.all_gather(gather_list, tensor)
3)broadcast
broadcast操作将一个进程的数据(如张量)发送到所有其他进程中。这通常用于当一个进程生成了某些数据,需要确保其他所有进程都得到相同的数据时。在在开始训练之前,可以用于同步模型的初始权重或者在所有进程中共享某些全局设置。一个示例代码如下:
import torch.distributed as dist
tensor_a = torch.tensor([1.0], device=device)
if rank == 0:
tensor_a.fill_(10.0) # 只有rank 0设置tensor_a为10
dist.broadcast(tensor_a, src=0) # rank 0将tensor_a广播到所有其他进程
3. 要实现DDP训练,我们需要解决哪些问题?
1)如何将数据均等拆分到每个GPU
在分布式训练中,为了确保每个GPU都能高效地工作,需要将训练数据均等地分配到每个GPU上。如果数据分配不均,可能导致某些GPU数据多、某些GPU数据少,从而影响整体的训练效率。
在PyTorch中,可以使用torch.utils.data.DataLoader结合torch.utils.data.distributed.DistributedSampler。DistributedSampler会自动根据数据集、进程总数(world size)和当前进程编号(rank)来分配数据,确保每个进程获取到的数据互不重复且均衡分布。
2)如何在IO操作时避免重复
在使用PyTorch的分布式数据并行(DDP)进行模型训练时,由于每个进程都是独立运行的,IO操作如打印(print)、保存(save)或加载(load)等如果未经特别处理,将会在每个GPU进程上执行。这样的行为通常会导致以下问题:重复打印(每个进程都会输出同样的打印信息到控制台,导致输出信息重复,难以阅读)、文件写入冲突(如果多个进程尝试同时写入同一个文件,会产生写入冲突,导致数据损坏或者输出不正确)、资源浪费(每个进程重复加载相同的数据文件会增加IO负担,降低效率和浪费资源)。
一个简单且可行的解决方案是只在特定进程中进行相关操作,例如,只在rank为0的进程中执行,如有必要,再同步到其他进程。
3)如何收集每个进程上的数据进行评估
在DDP训练中,每个GPU进程独立计算其数据的评估结果(如准确率、损失等),在评估时,可能需要收集和整合这些结果。
通过torch.distributed.all_gather函数,可以将所有进程的评估结果聚集到每个进程中。这样每个进程都可以获取到完整的评估数据,进而计算全局的指标。如果只需要全局的汇总数据(如总损失或平均准确率),可以使用torch.distributed.reduce或all_reduce操作直接计算汇总结果,这样更加高效。
4. 一个最简单的DDP代码框架
篇幅太长,见下篇。
五、查资料过程中的一个小惊喜
在查找DDP有关过程中,发现了一些博客和视频做得很不错,而且这里面有一部分是女生做的。博客和视频的质量都很高,内容安排合理,逻辑表达清晰,参考资料也很全面。我看到的时候,还是很惊艳的,巾帼不让须眉!链接如下:
国立中央大学的李馨伊
复旦大学的_Meilinger_