-
JDK7多线程并发环境HashMap死循环infinite loop,CPU拉满100%,Java
JDK7多线程并发环境HashMap死循环infinite loop,CPU拉满100%,Java
HashMap底层数据实现是数组+链表,链表在哈希碰撞后装入新数据,像是一个桶。
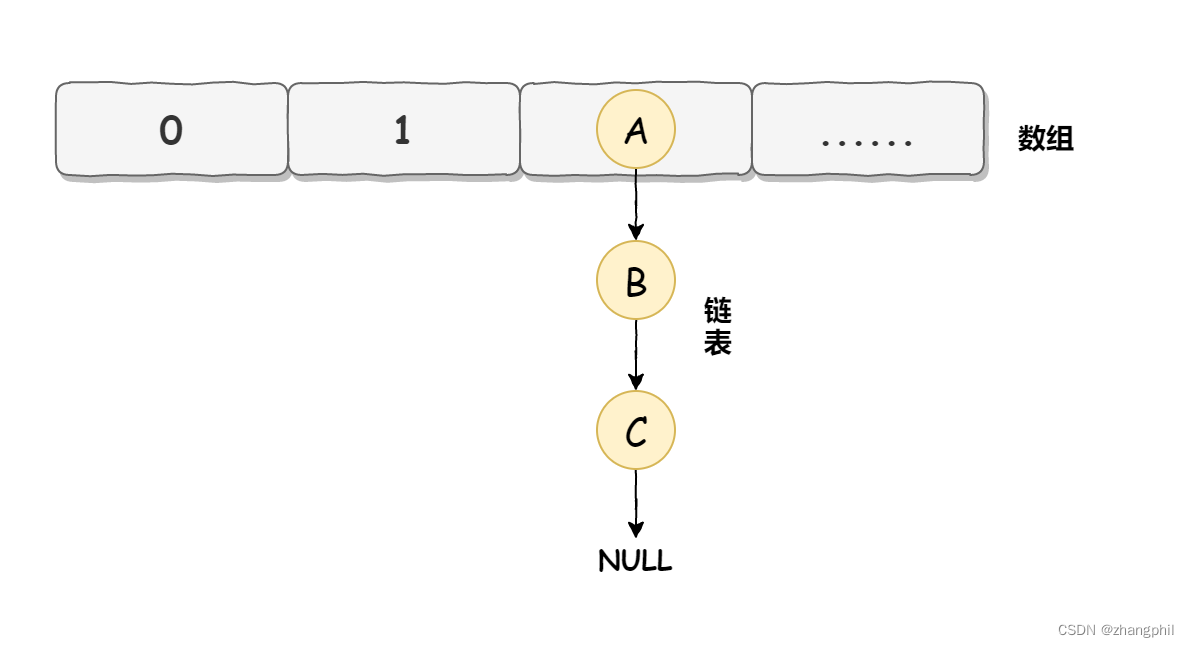
HashMap在JDK7的实现中,并发环境存在死循环infinite loop问题。导致的结果之一是程序在多线程并发环境下,运行到某些时机,CPU拉满100%,杀掉进程启动后程序恢复正常,但是再次启动,多线程的并发环境下再跑到一定时机(get操作后开始死循环),又会把CPU拉满100%(陷入死循环)。
HashMap在并发的多线程环境下扩容造成死循环。通常在初始化HashMap时候会有一个loadFactore负载因子比如0.75,当原先存储的元素size达到固有长度的0.75后,开始扩容,扩容过程用头插法把oldTable单链表的节点插入到newTable单链表,newTable单链表倒置了oldTable中的单链表。

于是,多线程并发扩容场景下很可能导致扩容后的HashMap产生一个有环的单链表,进而导致后续get取数据陷入死循环,CPU拉满100%。
新链表的顺序跟旧的链表是完全相反的,只要保证建新链还是原来顺序就不会产生循环,JDK8用 head 和 tail 来保证链表顺序和之前一样,就不会产生循环引用。
结论:JDK8中,Java修正了该问题,但HashMap始终存在线程安全问题,比如并发put会发生数据覆盖,所以避免在多线程并发环境用HashMap,如果是并发多线程环境,请:
1、ConcurrentHashMap替代HashMap。
2、使用 synchronized 或 lock 加锁HashMap。(效率低)
LinkedHashMap实现LRU缓存cache机制,Kotlin_zhangphil的博客-CSDN博客* * 基于Java LinkedList,实现Android大数据缓存策略 * 作者:Zhang Phil * 原文出处:http://blog.csdn.net/zhangphil * * 实现原理:原理的模型认为:在LinkedList的头部元素是最旧的缓存数据,在L_android大数据缓存。一句话概括的说:两者最大的不同就是,HashMap不保证put进去的数据的顺序;例如,假如在HashMap中依次、顺序添加元素:1,2,3,4,5,在遍历HashMap时输出的顺。
https://blog.csdn.net/zhangphil/article/details/132604797Java的HashMap与LinkedHashMap异同_zhangphil的博客-CSDN博客一句话概括的说:两者最大的不同就是,HashMap不保证put进去的数据的顺序;而LinkedHashMap则保证put进去的数据的顺序。换句话也就是说,HashMap添加进去的数据顺序和遍历时的数据顺序不一定;而LinkedHashMap则保证添加时数据顺序是什么,遍历时数据顺序是什么。例如,假如在HashMap中依次、顺序添加元素:1,2,3,4,5,在遍历HashMap时输出的顺
-
相关阅读:
一键式AI智能剪辑,轻松处理视频,释放无限创意!“
LabVIEW Modbus通讯稳定性提升
腾讯推理框架TNN简介
为什么你的shopee虾皮店铺越做越垮?极有可能是这三点没做好?
ESP8266-Arduino编程实例-MCP9808数字温度传感器驱动
React 中 useState 清理的必须性
modbusRTU通信简单实现(使用NModbus4通信库)
Web后端的前端:揭秘跨界融合的深度探索
Stream API
自定义View中的ListView和ScrollView嵌套的问题
- 原文地址:https://blog.csdn.net/zhangphil/article/details/132666022